WeaMind Infra 介紹:VM、Load Balancer 與雲端架構
![]()
📌 這是 WeaMind 系列 的第 7 篇。
本系列以真實世界專案為背景,記錄重要技術實作與經驗分享。
WeaMind 跑在什麼上面?
最早是單一台 VM + 容器化部署,而現在就複雜多了——K3s cluster、多台 VM、Load Balancer。
這篇要介紹 WeaMind 的基礎設施——cloud infra 層。後續會有好些 K8s 相關文章,都會以這個架構為基礎,所以先把前提講清楚。
簡單來說是:4 台 VM + 1 個 Load Balancer,全部跑在 Hetzner Cloud 上,月費大約一千台幣。
K8s 相關設定,都已公開在這個 GitHub 專案:weamind-infra。歡迎參考、指教。
總覽:WeaMind 的硬體組成
我們先看一下全貌:
| 元件 | 規格 | 角色 |
|---|---|---|
| 堡壘機 | CAX21(Arm,4C/8GB) | 資料層 + SSH 跳板 |
| Control Plane | CX23(x86,2C/4GB) | K8s API Server |
| Worker × 2 | CX23(x86,2C/4GB) | 跑應用 Pod |
| Load Balancer | LB11 | 外部入口 |
這四台機器都在同一個 Hetzner Private Network 裡。內網 IP 分別是 10.0.0.2 至 10.0.0.5。
K8s 三台 node 不暴露公網。平常操作是在本機或堡壘機(Bastion host)用 kubectl 控制 cluster。這也是常見的小型 K8s 部署架構。
延伸閱讀:《關於我怎麼把一年內學到的新手 IT/SRE 濃縮到 30 天筆記這檔事》 Day 02 基礎架構設定 - 網路架構
實際上,我就是從上述這篇文章第一次認識到堡壘機的。
整體呈現一個「混合架構」:應用層(LINE Bot)跑在 K8s 叢集,可以彈性擴充,資料層(PostgreSQL、Redis)則留在堡壘機。彼此透過內網連接。
堡壘機:原本的單機版 VM
這台機器的角色有點特別。
最早的 WeaMind 是單機版,整個應用就跑在這台 VM 上——App、Nginx、Docker、PostgreSQL、Redis,全部塞在一起。
後來把應用層搬進 K8s 叢集,這台就「退役」成堡壘機,但資料還是留在這裡。
什麼是堡壘機?
堡壘機(Bastion host)是內網中唯一暴露公網 IP 的機器,作為進入內部網路的跳板。
所有 SSH 連線都必須先經過它,再從內網連到其他機器。這樣的設計減少了攻擊面——只需要守住一個入口,而不是讓每台機器都暴露在外。
在 WeaMind 的架構中,堡壘機除了當跳板,還兼任資料層的角色。這不是標準做法,但對小型專案來說,把兩個功能放在同一台機器可以省下不少成本。
主要規格與運行中服務
規格是 Hetzner 的 CAX21,Arm 架構,4 核 8GB。跑三個東西:
- PostgreSQL:存放天氣資料。
- Redis:分散式鎖、Rate Limiter。
- weamind-data:ETL daemon 程式,定期抓中央氣象署的天氣 API 資料,並更新至 PostgreSQL。
除了上述這些,我在這台 VM 還運行了好幾個開源服務,比如替代 GA4 的 Umami;替代 WakaTime 的 Wakapi 等。當然,還少不了負責流量轉發與 TLS 憑證的 Nginx 與 Certbot。
儘管如此,它們總共也只佔了 1.2 GB 的 RAM,對於這台有 8 GB RAM 的機器,顯然還是浪費了!
之後預計把 kube-prometheus-stack 中,前兩大吃資源的 Pod——Prometheus 與 Grafana——移到這台上。
為什麼資料層不搬進 K8s?
三個理由:
- 學習聚焦:K8s Stateful 管理是另一個大坑,不納入這次的範圍。
- 成本考量:不需要額外搞 PV、StorageClass。
- 資源利用:堡壘機是最大台的 VM,不多跑點東西太浪費😎
總之,堡壘機確實做了不少事情,但資源上還游刃有餘。如何有效利用剩下的空間,是我接下來的課題。
K8s 叢集:三台節點
K8s 叢集的部署方案採用 K3s,配置為 1 Control Plane + 2 Worker。
三台都是 CX23:x86 架構,2 核 4GB。
這個規格對 K3s 來說綽綽有餘。K3s 本身很輕量,Control Plane 不需要太多資源;而 WeaMind 的 LINE Bot 本質上就是用 FastAPI 寫的 webhook server,也很輕量。
為什麼要兩台 Worker 而不是一台?主要是為了高可用:如果一台 VM 掛了,Pod 可以在另一台重新調度,不會整個服務中斷。或者更簡單的理由——帥!
至於為什麼選 K3s 而不是 kubeadm,我在〈K3s 是什麼?為什麼我選擇用 K3s 部署 WeaMind〉已有說明,這裡不重複。
網路連線與防火牆
安全設計上,這三台雖然有公網 IP(方便更新),但防火牆只允許內網流量,外部無法直接連入。
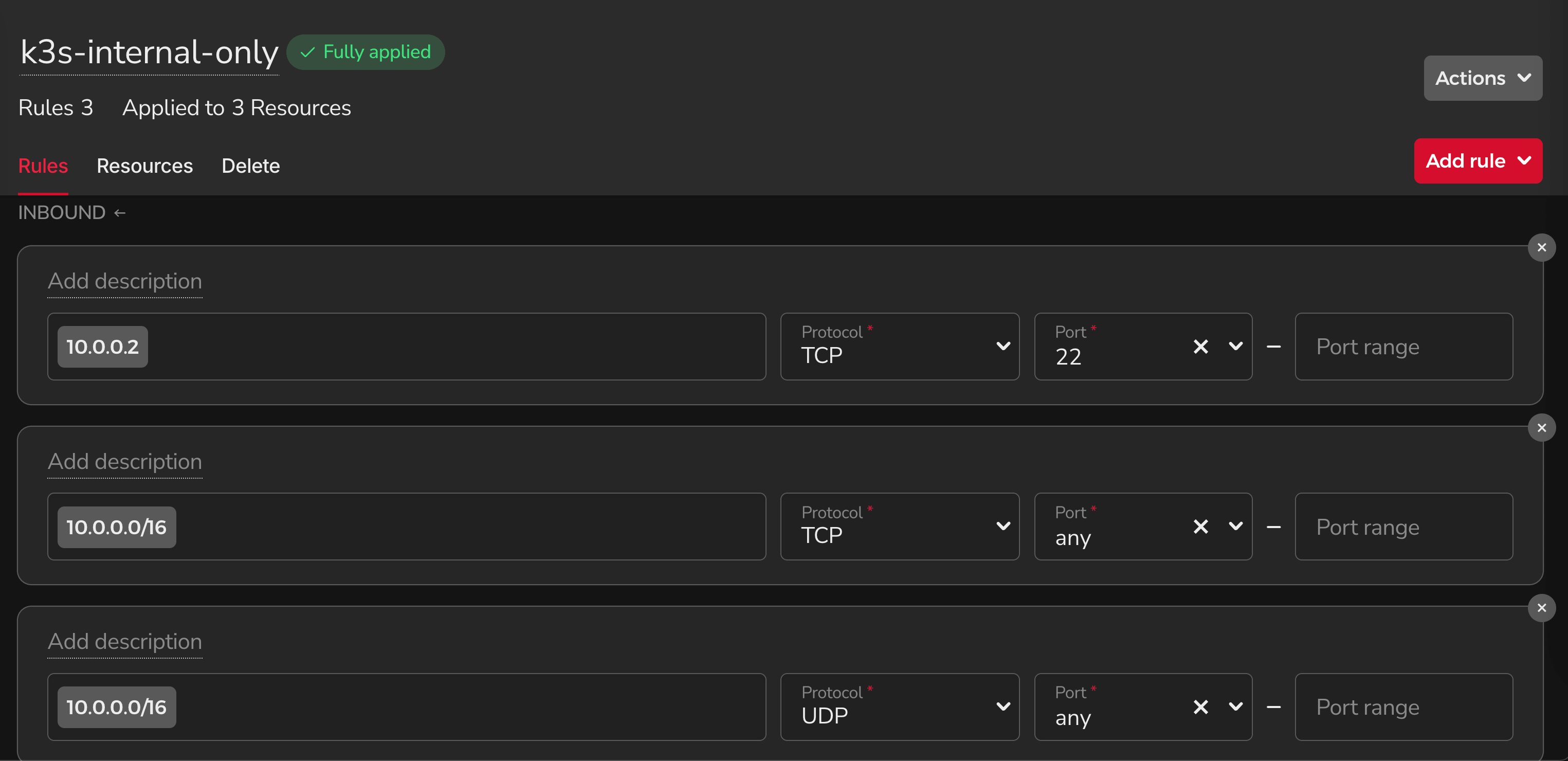 防火牆規則
防火牆規則
要管理它們,必須先 SSH 到堡壘機,再從內網連進去。而對外的流量入口只有一個:Hetzner Load Balancer。
成本與選型考量
Hetzner 在今年 4 月與 6 月連續兩次漲價,據官方公告,主因是記憶體供不應求,導致巨大成本壓力(AI 熱潮的連鎖效應)。
我的機器是今年年初建立的,目前適用 4 月調整後的「舊」價格。如果你現在要開新機器,則會是 6/15 後的新價格。
價格對照:
| 元件 | 舊價格(4 月後) | 新價格(6/15 後) |
|---|---|---|
| CAX21 | €7.99 | €10.49 |
| CX23 × 3 | €11.97(單台 €3.99) | €16.47(單台 €5.49) |
| LB11 | €7.49 | €7.49 |
| 固定 IP × 4 | €2.00 | €2.00 |
| 總計 | €29.45 | €36.45 |
換算成台幣,大約是 NT$1,020 到 NT$1,260。
至於為什麼選 Hetzner,我在〈在 Hetzner 開新 VM 指南〉有比較詳細的說明。簡單講就是:便宜、穩定。
但有一好沒兩好,它的缺點則是延遲偏高,對於重視用戶體驗的服務可能不適合。
結語:打開新世界的大門
這個規模對 Side Project 來說,無疑是 overkill 了。如果不是 Hetzner 的價格優勢(雖然不得已漲了兩次價),我大概也不會想自己維護一個 K8s cluster。
其實,大多數 Side Project 用一台 VM 就能搞定——但我選擇擁有叢集。
不只是為了磨練技術,而是當你真的擁有一個 cluster,你的角色就不一樣了——你是這個系統的管理者,不是單純的開發者。
這樣的心態轉變,對我而言,就像打開新世界的大門——再也回不去了。